鸽了好久了
ReadAsm2 读汇编是逆向基本功。
给出的文件是func函数的汇编 main函数如下 输出的结果即为flag,格式为flag{**********},请连flag{}一起提交
编译环境为linux gcc x86-64 调用约定为System V AMD64 ABI 请不要利用汇编器,IDA等工具。。这里考的就是读汇编与推算汇编结果的能力
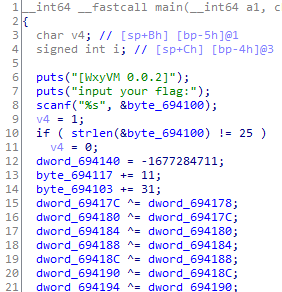
1 2 3 4 5 6 7 8 9 int main (int argc, char const *argv[]) char input[] = {0x0 , 0x67 , 0x6e , 0x62 , 0x63 , 0x7e , 0x74 , 0x62 , 0x69 , 0x6d , 0x55 , 0x6a , 0x7f , 0x60 , 0x51 , 0x66 , 0x63 , 0x4e , 0x66 , 0x7b , 0x71 , 0x4a , 0x74 , 0x76 , 0x6b , 0x70 , 0x79 , 0x66 , 0x1c }; func(input, 28 ); printf ("%s\n" ,input+1 ); return 0 ; }
参考资料: https://github.com/veficos/reverse-engineering-for-beginners 《汇编语言》王爽 《C 反汇编与逆向分析技术揭秘》
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 00000000004004e6 <func>: 4004e6: 55 push rbp 4004e7: 48 89 e5 mov rbp,rsp 4004ea: 48 89 7d e8 mov QWORD PTR [rbp-0x18],rdi 4004ee: 89 75 e4 mov DWORD PTR [rbp-0x1c],esi 4004f1: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1 4004f8: eb 28 jmp 400522 <func+0x3c> 4004fa: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] 4004fd: 48 63 d0 movsxd rdx,eax 400500: 48 8b 45 e8 mov rax,QWORD PTR [rbp-0x18] 400504: 48 01 d0 add rax,rdx 400507: 8b 55 fc mov edx,DWORD PTR [rbp-0x4] 40050a: 48 63 ca movsxd rcx,edx 40050d: 48 8b 55 e8 mov rdx,QWORD PTR [rbp-0x18] 400511: 48 01 ca add rdx,rcx 400514: 0f b6 0a movzx ecx,BYTE PTR [rdx] 400517: 8b 55 fc mov edx,DWORD PTR [rbp-0x4] 40051a: 31 ca xor edx,ecx 40051c: 88 10 mov BYTE PTR [rax],dl 40051e: 83 45 fc 01 add DWORD PTR [rbp-0x4],0x1 400522: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] 400525: 3b 45 e4 cmp eax,DWORD PTR [rbp-0x1c] 400528: 7e d0 jle 4004fa <func+0x14> 40052a: 90 nop 40052b: 5d pop rbp 40052c: c3 ret
相关知识
1、
-word 表示字
q 四字 d 双字
dword qword
dword 216 =32 位 qword 4 16 = 64 位
2、PTR 指针(pointer)
没有寄存器名时, X ptr 指明内存单元的长度,X 在汇编指令中可以为word,byte,dword, qword
3、内存地址[rbp-0x18]
4.movsxd 指令为扩展至零 将32位的寄存器和内存操作数符号扩展到64位的寄存器 5.逻辑异或运算指令 XOR XOR OPRD1,OPRD2 实现两个操作数按位‘异或’(异为真,相同为假)运算,结果送至目的操作数中. OPRD1<–OPRD1 XOR OPRD2 6.JLE 小于等于时转移
L:less
E:eather
G:gather
分析
摘自https://www.cnblogs.com/Chesky/p/nuptzj_re_writeup.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 push rbp /*函数调用 4004e7: 48 89 e5 mov rbp,rsp */ 4004ea: 48 89 7d e8 mov QWORD PTR [rbp-0x18],rdi //rdi 存第一个参数 4004ee: 89 75 e4 mov DWORD PTR [rbp-0x1c],esi //esi 存第二个参数 4004f1: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1 //在[rbp-0x4]写入 0x1 4004f8: eb 28 jmp 400522 <func+0x3c> 4004fa: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] //把[rbp-0x4]的值送入 eax ,即 eax = 1 4004fd: 48 63 d0 movsxd rdx,eax //扩展,传送 rdx=1 400500: 48 8b 45 e8 mov rax,QWORD PTR [rbp-0x18] //第一个参数 [rbp-0x18],rax=input[0] 400504: 48 01 d0 add rax,rdx //rax = input[1] 400507: 8b 55 fc mov edx,DWORD PTR [rbp-0x4] //第 6 行中存储的 0x1 ,传入 edx ,即 edx =1 40050a: 48 63 ca movsxd rcx,edx //rcx=1 40050d: 48 8b 55 e8 mov rdx,QWORD PTR [rbp-0x18] // rdx = input[0] 400511: 48 01 ca add rdx,rcx //rdx += rcx ,rdx = input[1] 400514: 0f b6 0a movzx ecx,BYTE PTR [rdx] //ecx = input[1] 400517: 8b 55 fc mov edx,DWORD PTR [rbp-0x4] //edx = 0x1 40051a: 31 ca xor edx,ecx //edx ^= ecx ,原先 ecx 为 1100111,edx 为 0000001,操作后 edx 为 1100110,即 f 40051c: 88 10 mov BYTE PTR [rax],dl //rax = dl 40051e: 83 45 fc 01 add DWORD PTR [rbp-0x4],0x1 //[rbp-0x4]处为 0x1 400522: 8b 45 fc mov eax,DWORD PTR [rbp-0x4] //把[rbp-0x4]的值送入 eax 400525: 3b 45 e4 cmp eax,DWORD PTR [rbp-0x1c] // 比较操作,将[rbp-0x1c] 处的值和eax的值作差 400528: 7e d0 jle 4004fa <func+0x14> //eax < 28 时跳转至 4004fa func(input, 28); 40052a: 90 nop 40052b: 5d pop rbp 40052c: c3 ret
编写源代码
1 2 3 4 5 6 a = [0x0 , 0x67 , 0x6e , 0x62 , 0x63 , 0x7e , 0x74 , 0x62 , 0x69 , 0x6d , 0x55 , 0x6a , 0x7f , 0x60 , 0x51 , 0x66 , 0x63 , 0x4e , 0x66 , 0x7b , 0x71 , 0x4a , 0x74 , 0x76 , 0x6b , 0x70 , 0x79 , 0x66 , 0x1c ] for i in range(28 ): print(chr(i^a[i]),end='' )
Py交易 下载py文件,在线反编译https://tool.lu/pyc/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import base64def encode (message ): s = '' for i in message: x = ord(i) ^ 32 x = x + 16 s += chr(x) return base64.b64encode(s) correct = 'XlNkVmtUI1MgXWBZXCFeKY+AaXNt' flag = '' print 'Input flag:' flag = raw_input() if encode(flag) == correct: print 'correct' else : print 'wrong'
据此写出解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import base64 def decode(message): s='' message = (base64.b64decode(message)) print(message) for i in message: s += chr((ord(chr(i))-16) ^ 32) #需要注意的是,base64解码出来的是二进制流,所以先要用chr(i)转化为字符,再操作 return s correct = 'XlNkVmtUI1MgXWBZXCFeKY+AaXNt' flag = decode(correct) print(flag)
WxyVM 输入的字符串进行加密后与已知字符串比较。加密为15000个字符,三个一组,进行5000次。每组中,第一个字符为加密类型,有五种case;第二个字符表示对输入的字符串中第几个字符加密;第三个字符为加密的参数。
反过来解密即可。
IDC提取15000个字符。
1 2 3 4 5 6 7 8 9 10 11 12 static main() { auto i,fp; fp = fopen("d:\\dump","wb"); auto start = 0x6010C0; auto size = 15000; for(i=start;i<start+size;i++) { fputc(Byte(i),fp); } fp.close(); }
python解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 s = [0xc4 ,0x34 ,0x22 ,0xb1 ,0xd3 ,0x11 ,0x97 ,0x7 , 0xdb ,0x37 ,0xc4 ,0x6 ,0x1d ,0xfc ,0x5b ,0xed ,0x98 ,0xdf ,0x94 ,0xd8 ,0xb3 ,0x84 ,0xcc ,0x8 ] with open('dump' , 'rb' ) as f: dump = f.read() for i in range(15000 //3 -1 , -1 , -1 ): operation = int(dump[i*3 ]) offset = int(dump[i*3 +1 ]) number = int(dump[i*3 +2 ]) if operation == 1 : s[offset] -= number elif operation == 2 : s[offset] += number elif operation == 3 : s[offset] ^= number elif operation == 4 : s[offset] //= number elif operation == 5 : s[offset] ^= s[number] for i in s: print(chr(i&0x7f ),end='' )
有两点需要注意:
由于是byte类型,所以要注意溢出(&ff),当然如果解密没问题,flag的ascii肯定在127以内,所以&7f也可以。
开始时我写的是for i in range(15000//3-1, 0, -1),这样第0组没有参与解密,所以有一个字符最终不对,ascii是15,因为是不可见字符,所以没打印出来,导致flag长度为23,而不是24。幸好这次没打印出来,不然我死活找不到错误原因。
maze 攻防世界做过,然鹅这次还是没有独立做出了,看了之前的题解才更好地理解了代码。
就走迷宫。
之前的题解:攻防世界逆向新手区题解-0x0C maze
WxyVM 2
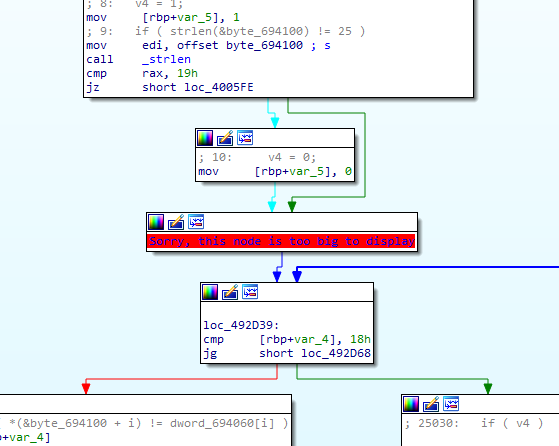
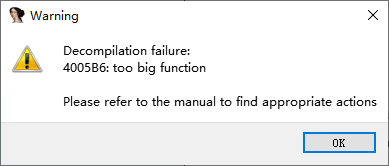
主函数的一部分无法显示在图形窗口中,换成文本窗口。
IDA7.0无法转C:
IDA6.8中转C,大约反编译了5分钟。
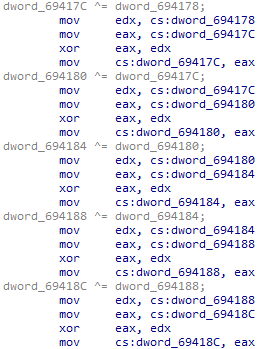
输入一个字符串byte694100,加密后与已知字符串dword_694060比较。
加密长达25000行的混淆,其实只有对byte_6941??(??为0~24)的加密是有用的。所以在于从25000行的代码中提取有效的代码。
在伪C代码的界面ctrl+a全选,复制到txt中,删掉首尾的非加密代码。
下面的脚本输出所有包含byte_6941??(??为0~24)的行,以便于归纳分析。
1 2 3 4 5 6 7 8 9 10 import rewith open('WxyVM2.txt' ,'r' )as f: t = f.readlines() t = [i.strip() for i in t] for i in t[::-1 ]: r = re.search(r'byte_6941(.{2})' , i) if r and 0 <= int(r.group(1 ), 16 ) <= 25 : print(i)
注意re.search(r'byte_6941(.{2})', i),不要写成re.search(r'byte_6941(\d{2})', i),我被坑了。因为地址是十六进制的。
分析可知有五种运算,加、减、异或、自增、自减。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import rewith open('WxyVM2.txt' ,'r' )as f: t = f.readlines() t = [i.strip() for i in t] list = [0xc0 ,0x85 ,0xf9 ,0x6c ,0xe2 ,0x14 ,0xbb ,0xe4 ,0x0d ,0x59 ,0x1c ,0x23 ,0x88 ,0x6e ,0x9b ,0xca ,0xba ,0x5c ,0x37 ,0xff ,0x48 ,0xd8 ,0x1f ,0xab ,0xa5 ] def str2int (str ): r = re.search(r'^(?:0x)?(.+?)u$' , str) if r: return int(r.group(1 ), 16 ) else : return int(str) for i in t[::-1 ]: r = re.search(r'byte_6941(.{2})' , i) if r and 0 <= int(r.group(1 ), 16 ) <= 25 : print(i) offset = int(r.group(1 ),16 ) r = re.search(r'byte_6941.{2} (.)= (.+?);' , i) if r: number = str2int(r.group(2 )) op = r.group(1 ) if op == '+' : list[offset] -= number elif op == '-' : list[offset] += number elif op == '^' : list[offset] ^= number print('list[%d] %s= %d' %(offset,op,number)) else : r = re.search(r'^(?:\+\+|--)byte_6941.{2};' , i) if r: if i[:2 ] == '++' : list[offset] -= 1 print('--list[%d];' %offset) elif i[:2 ] == '--' : list[offset] += 1 print('++list[%d];' %offset) print() for i in list: print('%4s' %str(chr(i&0x7f )),end='' ) print() for i in list: print('%4s' %str(i&0x7f ), end=' ' ) print() for i in list: print(chr(i&0x7f ),end='' )
注意for i in t[::-1]:,要倒着运算。我忘了这一茬了,导致看了别人的题解才恍然大悟。
顺便放一个提取某函数的汇编代码的IDC脚本,虽然这道题没用到。
来源:谁能告诉我ida怎么用脚本取函数代码啊_12楼
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include "idc.idc" static ElementExist(arrayid,size,val) { auto i,v; for(i=0;i<size;i++) { v=GetArrayElement(AR_LONG,arrayid,i); if(v==val) return 1; } return 0; } static GenFuncIns(st,arrayid,size) { auto start,end,i,ins,x,xt,funcend; start=st; end=FindFuncEnd(start); for(i=start;i<end;) { ins=GetDisasm(i); for(x=Rfirst(i);x!=BADADDR;x=Rnext(i,x)) { xt=XrefType(); if(xt == fl_CN && !ElementExist(arrayid,size,x)) { SetArrayLong(arrayid,size,x); size++; } } i=ItemEnd(i);/*FindCode(i,1);*/ //Message(form("%s\r\n",ins)); } return size; } static main() { auto arrayid,size,pos,st,file,funcend,path; st=ScreenEA(); path = GetIdbPath(); path = substr(path, 0, strlen(path) - 4) + "Part.asm"; file=fopen(path,"w+"); if(st==BADADDR) { Warning("您需要选中一个函数起始地址!"); return; } arrayid=CreateArray("gen_func_ins"); if(arrayid<0) { arrayid=GetArrayId("gen_func_ins"); } pos=0; SetArrayLong(arrayid,pos,st); size=1; for(pos=0;pos<size;pos++) { st=GetArrayElement(AR_LONG,arrayid,pos); Message(form("proc:%8.8x\r\n",st)); funcend=FindFuncEnd(st); if (funcend!=BADADDR) { Message("正在将这个函数代码写入 %s \n",path); GenerateFile(OFILE_ASM,file, st,funcend, 0); } else { Message(form("proc:%8.8x Write false\r\n",st)); } size=GenFuncIns(st,arrayid,size); } DeleteArray(arrayid); fclose(file); Message("All done, exiting...\n"); }
使用前把光标置于要提取的函数内部。生成的文件放在当前打开的 idb 文件目录下,文件名由 idb 的文件名加上 Part 组成,后缀.asm
你大概需要一个优秀的mac 非常基础的逆向题,就是异或。
IDC提取数据
1 2 3 4 5 6 7 8 9 10 11 12 static main() { auto i,fp; fp = fopen("d:\\dump","wb"); auto start = 0x100000ED0; auto size = 0x100000FAF - 0x100000ED0; for(i=start;i<start+size;i++) { fputc(Byte(i),fp); } fp.close(); }
python解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 with open('dump' , 'rb' ) as f: dump = f.read() list = [] for i in range(len(dump)//4 +1 ): list.append(dump[i*4 ]) for i in range(len(list)): if i >= 40 : list[i] ^= 0xef elif i>= 30 : list[i] ^= 0xab elif i>= 20 : list[i] ^= 0xef elif i>= 10 : list[i] ^= 0xbe else : list[i] ^= 0xad for i in range(len(list)): list[i] ^= 0xde for i in list: print(chr(i),end='' )
480小时精通C++ 如果能忽略花里胡哨的东西,其实不难。
加密函数:
子函数:
480个子函数其实基本一样,就是改一下涂黄处的数值。从001到480。
string :: operator []的返回值是字符串中指定位置的字符。
设定s是flag,sn是key(形如480480480),i是下标。所以加密就是s[i] = sn[i%len(sn)] ^ s[i] ^ i,解密就是再异或一次,不过注意要从480倒着向001解密。
对了,程序给出的加密后的字符串,是十六进制,不是直接的加密后的字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def get_str (num ): if num>=100 : return (str(num))*3 elif num>=10 : return ('0' +str(num))*3 else : return ('00' +str(num))*3 s = '62646163734e346a6f60715f673c6e5b4561777c337657635b7831717b5f74447577297d' ls = [] for i in range(len(s)//2 ): ls.append(int(s[i*2 :i*2 +2 ], 16 )) print(ls) for n in range(480 ,0 ,-1 ): sn = get_str(n) print(sn) for i in range(len(ls)): ls[i] = ord(sn[i%len(sn)]) ^ ls[i] ^ i for i in ls: print(chr(i),end='' )
Our 16bit wars 分值不高,提示也说很简单。但是做出来的很少,只有10个人。可能是大多数bin狗离了伪C代码就活不下去了的缘故。
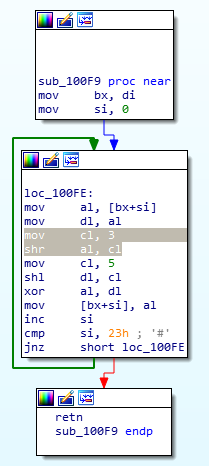
en,本题16位,无法反编译成C.
字符串长度23h。上图两处涂色,第一处为加密函数,第二处为比较字符串是否相等的函数。
加密函数:
SHR指令将目的操作数顺序右移1位或CL寄存器指定的位数。逻辑右移1位时,目的操作数的最低位移到进位标志位CF ,最高位补零。
所以加密就是输入字符左移5位和输入字符右移3位异或。
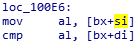
比较函数为:
0x76处有23h的数据,所以0x23处就是输入的字符串。
1 2 3 4 5 6 7 s = [0xC9 ,0x68 ,0x8A ,0xC8 ,0x6F ,0x07 ,0x06 ,0x0F ,0x07 ,0xC6 ,0xEB ,0x86 ,0x6E ,0x6E ,0x66 ,0xAD ,0x4C ,0x8D ,0xAC ,0xEB ,0x26 ,0x6E ,0xEB ,0xCC ,0xAE ,0xCD ,0x8C ,0x86 ,0xAD ,0x66 ,0xCD ,0x8E ,0x86 ,0x8D ,0xAF ] for i in s: for c in r'!"#$%&()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~' + '\'' : n = ord(c) if ((n>>3 ) ^ (n<<5 )) & 0xff == i: print(c,end='' ) break
16位程序,注意处理溢出,&0xff.