你不会真的看见这个标题就会点进来吧,不会吧不会吧不会吧?
前言 最近看到一个特别漂亮的小姐姐的写真图,便到处找合集里面的其他图片,结果无意中发现了一个宝藏网站 ,福利蛮多的,大概有一千多个合集。开通了一个月的会员后,开始分析如何自动化地将所有文件下载下来,毕竟文件太多了,一个一个下载,估计很容易”上火“。
模拟登录 因为只有会员可以下载福利文件,所有首先需要模拟登录该网站。没有验证码,所以模拟登录很容易实现。
这里我的思路是采用selesium获取cookies,并保存至文件。下次程序运行时先判断是否存在cookies文件,若存在,则不用再次模拟登录。如果cookies过期了,需要手动删除cookies文件,然后再次运行程序。
可能会报错,什么path之类的,这是因为缺一个插件,去报错中提示的网站下载chromedriver_win32.zip并运行即可。
1 2 3 4 5 6 7 8 9 driver = webdriver.Chrome() driver.get('http://aitaosir.icu/wp-login.php' ) time.sleep(1 ) user = driver.find_element_by_id('user_login' ).send_keys('用户名' ) time.sleep(1 ) pwd = driver.find_element_by_id('user_pass' ).send_keys('密码' ) time.sleep(1 ) submit = driver.find_element_by_id('wp-submit' ).click() cookies = driver.get_cookies()
此时获取的cookies是列表,里面有字典,我们需要转化一下格式,并写入session中
1 2 3 4 5 self.session=requests.Session() c = requests.cookies.RequestsCookieJar() for item in cookies: c.set(item["name" ],item["value" ]) self.session.cookies.update(c)
提取链接
绝大多数资源都有百度云、站长自搭网盘(其实就是onedrive)两种分享方式。
百度云分享的资源的文件名没有可读性,因此,我最初想通过获取站长自搭网盘的文件外链,囤起来,搭一个本地aria2慢慢下载。但当我已经拿到所有的资源的外链时,才发现,这些链接只有一个小时的时效。吐血了我都。所以又改为百度云。
上图的链接形如:http://aitaosir.icu/wp-content/plugins/erphpdown/download.php?postid=13247&url=&key=2
get传值返回百度云链接。
正则提取即可。注意上图只是正则的格式之一,还有一种格式,注意分布在前期的文章中。
百度云分享链接的转存 网上的接口教程大多失效了,在52破解上找到一个几个月前的新代码,虽然感觉这个代码不是很好看,很多地方考虑的也不全面,但最基本的转存还是可以实现的。
链接:Python 爬取某小说网站+转存到百度网盘
1 2 3 4 5 6 # furl = 分享链接 # verify = 提取码 # savepath = 转存到百度网盘指定目录 # BDUSS = 从百度COOKICES中提取 # STOKEN = 从百度COOKICES中提取 # bdstoken = 从百度COOKICES中提取
说几点:
保存至根目录下的zy文件夹,savepath为’zy’
bdstoken我没在cookies中找到,但是可以在network中搜索这个关键词,在请求的url中可以找到
由于是轮子,所以不深究了吧。
需要说一下的是,轮子中只能转存形如https://pan.baidu.com/s/1MP8QOmrDJVKpwmLOnE6-TQ的链接,而不能转存形如
https://pan.baidu.com/share/init?surl=MP8QOmrDJVKpwmLOnE6-TQ的链接。
以上两个链接其实指向的是同一个文件,所以稍微改动一下代码就可以了。
注意1MP8QOmrDJVKpwmLOnE6-TQ和MP8QOmrDJVKpwmLOnE6-TQ,前者有1,后者没有。
emmmm,轮子中没有可虑的情况有很多,比如分享的文件已被删除等等。将就用吧,懒得去完善了。
ocr识别文件名 还要说一下,分享界面的文件的名称是图片,无法拿到文件名。
我最初想调用百度ocr的api,程序甚至都写好了,但是文字识别的效果实在不佳,遂放弃。
虽然没用到ocr,但还是在这里写一下吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from aip import AipOcrimport base64, redef ocr (): APP_ID = '' API_KEY = '' SECRET_KEY = '' client = AipOcr(APP_ID, API_KEY, SECRET_KEY) b64 = 'iVBORw0KGgoAAAANSUhEUgAAARsAAAAeCAIAAACT9S1xAAAJnElEQVR42uyafUyb1ffAb3kpdMBcV7sXqgXnHDPSZciinXSmcat1yrpmoI1Lm7EVgYYQqzIDQ0cKGnQESdWIigiaWkANWMQoVCMhKlgpQcSm0PJWqECxkCJYXp72/uLub8+33/K24cx3svv5697Tc869z809vfec5wmCEAIMBnOdCMBLgMHgiMJgcERhMDiiMBgMjigMBkcUBoMjCoPB/K2IWlpaur7vr+x2u9VqvfGXaXx83Gw2r62zuLjY1dXldrvxrsIR9RcNDQ0ZlzGZTKtpczics2fPru0xOzs7IyMjLy8PdX/77Tfk9oMPPliuXFxcnJKSslze0tKCrNra2q77Mzc3NysUiunpaVLi8XieffbZxsbG1UzefvttsVi8tlubzRYXF9fb24t3FY6ovzAYDJ2dnTwej06nr6adlZUlkUjW9sjlcsPDwz/66CPUnZqaeueddx544IF9+/YBAEwm04oh5EdkZCSPx2tubv4nNiiHw6mqqnrjjTdISXV1dVlZ2cGDB/GGwFzPWx+bzZZKpbt3715NOzMz8/jx42t7TE5O5vP5fsLTp08fPnwYxW1NTc2609q3b59UKt2+ffs/8cy7d+9OT09Xq9Wzs7MAAIIgCgoKFArFbbfdhjcE5vrnUU6nU6lU/vzzz6REp9O98sorAIDXXnutoaEBAOB2u5VKZW9v77vvvisSiSQSSVNT07qDVVVVabVagiCUSmVRUREpt1qtaWlpjz766AsvvOByuVa07enpSU9PFwqFZ86cMZlM33zzTXZ2tsfj8b1A6nQ6AEB7e3tKSsojjzySmpo6Ojq6orfc3Nz5+fm33noLAKDRaMbGxnJzc/v6+pRKJZkIDQ8PK5XKqakpP9vXX3+9vr5er9c/8cQTYrG4vr7e91ePx1NaWnrixAmpVPrDDz8AAEZGRpRKZV9fn+8F+9KlS3jz3SwRxWAwmpqaysrKfPffzMwMAECr1ba2tgIAFhYW1Gq1XC7//vvvRSIRlUo9fvz4GnnI/w8WEBAYGAgACAoKQg0AgMPhkEgkMTExx44dq6qqEgqFXq/Xz3BgYOD+++8nCEImk91xxx0jIyORkZElJSXffvstUhgdHc3JyaHT6T/++OORI0cYDIZUKmUwGOPj4yvOZOfOnQqFoqSkxOVyFRYWZmVlMZlMm82mVqsXFhaQztjYmFqtRg/uy8cff6xSqUpLSwUCQVBQUFJSUnt7O/mrUqk0m81isXh2dpbP53/33XcsFquuru79998ndXJyctDxiNmEwCvk5eUlJSWhdlFREZPJJAgCQmg0GikUSn9/P4QwPj7+ueeegxCitP7s2bOk+YkTJ3g8Hmp//vnnUVFRqP3LL7+QRUIIYWVlZUhICGn19NNPBwcHW61W1P3pp59Q5QB14+PjKysrIYRarRYAMDMzA304fPiwXC5H7VdffTUmJgZCeOnSJTqd7vF44Ho4HI7w8HA+n79t27apqSkIoV6vBwBMT08jBVQUGRwchBDm5+cj/xDChISEe+65By0OQRAsFuv555+HEFosFgDA+fPnkZrX6+VyuSKRCEL44osvRkdHI7nRaAwICBgaGoKYzcjK1XOZTOZ0OtEJoNFo+Hz+nj17lqudOnWKbD/88MOdnZ0bCOkDBw7ceeedqH3o0CEGg9HV1eWnw+PxIiIiHnrooc8++4y86aWmptbV1S0uLqJJnjt3DgBw7Nix2dlZgUDw9ddfk+b5+fmJVyDPEyaTmZmZ2dLScv78+TWKMSvC5/PRGRsYGHj33XdPTk4uXxMKhSIUCtGzyOVym82GhtZoNEePHo2KisL/5jfLrQ8AwGKxBAJBTU2Nx+Oprq5OS0tbUS00NNTvuNvADPycrOjn9ttv7+rqOnjwoFQq5XA46BWWRCIhCOKrr77q7u42m82ohBgXF9fR0bFz587HHnuMy+U6HA4AgEAgSLkCm80m3SYlJQEARCLRtc45KCiIbAcGBvpeU1dck6ioqKNHj2q1WrSeqampeOfdXBEFAEhJSamrq2tqaiIIwvcs8sU3SzEYDLGxsVd5z/TtTkxM+OZLTqeTw+Est9qzZ095efnAwMDS0tLLL78MAAgLCzt9+rRWq9VoNImJiTt27CAPPa1Wazab+/v7UYmcx+MlXyEyMpL0SaFQfIcICQlBtz7UtdlsG1hQvzUhnyUtLa22tra5uZkgiHVfbWE2YUSJxWII4cWLF2UyGZVKXVGnoKDAYrFACD/99NPq6uqMjIx1x7vlllsWFxdNJhNZUrNarS+99BJBEL///nt6evrevXsFAoGfVUdHR09PD4qiiIiI4OBgcps2NjbW1taSp2hra+vg4CAAYOvWrTQajdS8GmJjY6lUaklJCUEQdrt9Y+W43NzckZERr9dbUVHx5ZdfKhQKJD958iSFQsnOzj5z5gyVSkXJqsFgAADo9fo333wTADA5OXnhwgV0rmI2W0SFhoY++eSTRqPxqaeeWk1HIpEkJCTQaDSpVHrhwgWUyayNQCDYv39/bGwsl8tFEi6XazKZwsLCduzYMT4+rtPpfO9UCLvdHh8fv23bNjqdHhERUVBQgOT33ntvTExMQECAUChEkl9//fWuu+7avn37rl274uLinnnmmatfCzqdXlpaWl5eHhYWdt9998lksg0s6KlTpw4cOLBly5asrKzi4uLExEQkDw4ORnV/FPwul0ulUn3yyScAgIqKCpVKBQAwGo1FRUWoPIPZVLW+dUFXI71ePz8/b7FY5ubmfH9do9aH6mNWq9XlcvmajI2NDQ8P+41C1voghHNzc1ar1eFw+Cp4vd79+/erVCpf4czMjMViIUt218off/xhtVp9J3yt/PnnnxaLxe12+8kzMzOPHDlCdicmJtAobrfb6XQiod1ux+WyfzX/dRr09PTk5OScO3cOfTF0NYSEhOzdu9dXUlhY2N3d7aeWl5d36NChxx9/HKXyZHGPZNeuXb7dtrY2nU5nt9tJyZYtW5ZbffHFF0NDQ36naMRlNvwXE36Zv/MnRaPR/NYE3eg+/PDDiooKUkImfqGXQW3fNA/zb+Q/EXXy5En0GQ6NRvs7HtlsNpPJJJNvFouFXhbfeuutV+9k69at0dHR+fn56Nul5RgMhrKysvr6+sLCwjU+m7oRmJ+fR5/8JiQkJCcn4z23uaFsrOS9sLBQXFwslUqjo6P/J/Pu6+t77733HnzwQTJRuWFZWlq6ePEim82Wy+Wr1XgwN3tEYTCYa6v1YTAYHFEYDI4oDAZHFAaDwRGFwfzj/F8AAAD//6kMUE2wyZydAAAAAElFTkSuQmCC' image = base64.b64decode(b64) r = client.basicGeneral(image); print(r) result = re.search(r'words_result\': \[{\'words\': \'(.+?)\'}' , str(r)) print(result.group(1 )) if __name__ == '__main__' : ocr()
APP_ID,API_KEY,SECRET_KEY去百度云控制台找,要先开启文字识别的服务。
移动端获取文件名称 然后发现手机端的分享页面的文件名是可以复制的。
于是下载夜神模拟器,没想到可以通过chrome进行远程调试。
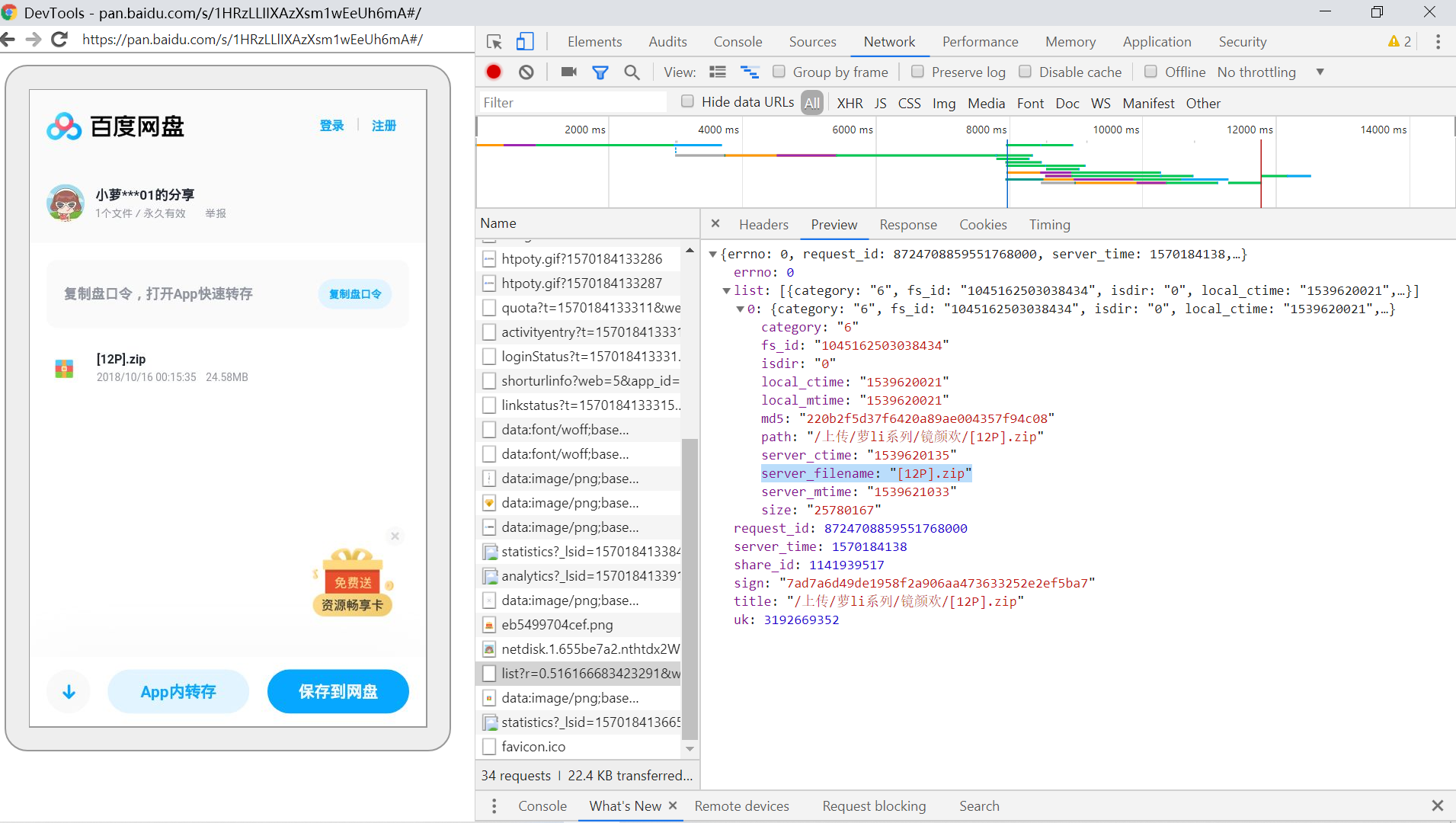
看到了文件名。
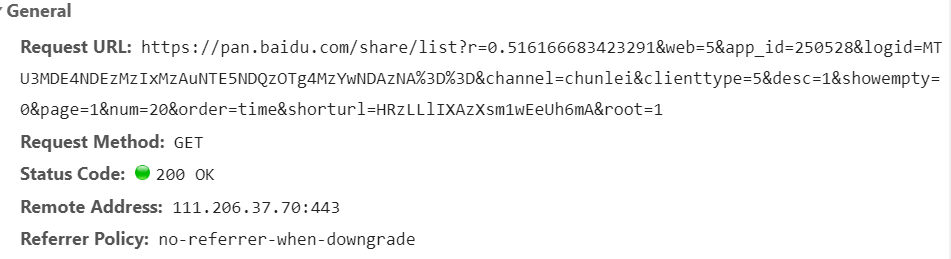
该请求为
虽然好多参数,但是大部分是不变的。r和logid虽然一直在变,但是实践证明随便给个固定值,也能返回正确的文件名。
shorturl就是前面说的形如1MP8QOmrDJVKpwmLOnE6-TQ和MP8QOmrDJVKpwmLOnE6-TQ中的后者。
返回的值含有\uxxxx,.encode('utf-8').decode('unicode_escape')转码一下就可以了。
然后写完了以后,才发现上面的轮子中的最终请求返回的json中除了含有状态码之外,同样也含有文件名称。
亏大了。为了写这个移动端获取文件名,我熬夜到早上5点40,结果发现你轮哥还是你轮哥
人工提取 程序跑完,发现还有几十个链接没被正则提取出来,发现只有站长自搭网盘的分享链接,没有百度云链接。
所以手动获取下载链接,粘贴到我自己搭建的aria2中下载,借助于阿里云高速的下载速度。
然后再从服务器取回文件。
名称替换 等到所有的文件从百度云下载下来之后,我想写个小脚本,把可读性很差的文件名,替换成可以当作网页标题的文件名。
后记 资源一共好几百G,发财了。硬盘又快满啦。
github链接:https://github.com/iyzyi/crawler/tree/master/aitaosir