水 and 菜
cycle graph
32位PE程序,使用ida分析。
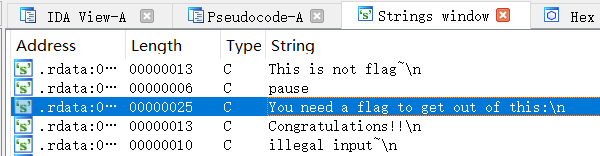
通过string定位到主函数。
这一段代码在输入字符串之前,进行数据的处理。其值与输入无关,所以可以直接使用OD提取相关数据。
输入字符串之后的关键代码:
v7为指针,指向前面所说的在输入字符串之前进行的运算的一片区域中的某个值。开始时v7指向0x403378.
v5初始值为48,之后的第i次循环都将赋值为flag[i-1]的值。
v12是输入的flag的基址。
v11是flag中的字符。
进行16次循环(v6=5~20),每次循环主要有如下运算:
若v7指向的数值加v5等于flag[i],则v7赋值为v7地址+4处的指针指向的一个地址
若v5减去v7指向的数值等于flag[i],则v7赋值为v7地址+8处的指针指向的一个地址
v5赋值为flag[i](但是赋值后的v5是在下一次循环中参与运算,所以其实相当于flag[i-1])
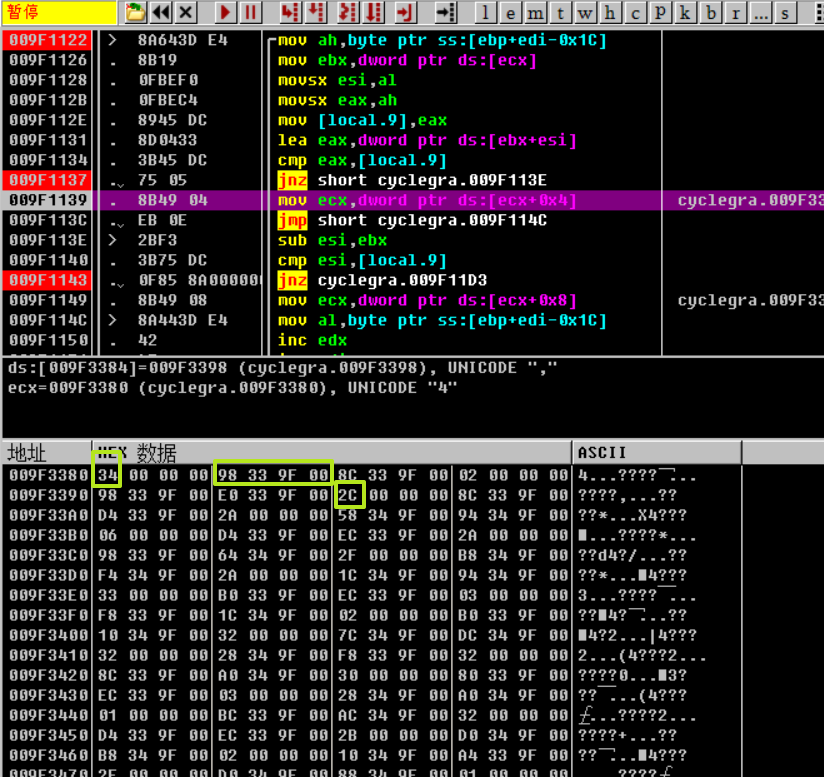
在OD中看一下运算过程:
最初v7(eax)=0x9f3380,其值为0x34,该值用于第一次循环中的运算判断。我们手动构造了满足地址+4条件的flag(第一个字符为d即可),v7+4后的地址处的数据是0x9f3398,其值为0x2c,该值用于下一个循环。
以上过程循环十六次。
我们在hex区提取出该区域的所有值。
通过脚本可以得到整理后的数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import redef little_egg (s ): return s[10 :12 ] + s[7 :9 ] + s[4 :6 ] + s[1 :3 ] def hex_format (num ): return '00' +hex(num)[2 :].upper() data = '''00983378 98 33 98 00 00 00 00 00 34 00 00 00 98 33 98 00 00983388 8C 33 98 00 02 00 00 00 98 33 98 00 E0 33 98 00 00983398 2C 00 00 00 8C 33 98 00 D4 33 98 00 2A 00 00 00 009833A8 58 34 98 00 94 34 98 00 06 00 00 00 D4 33 98 00 009833B8 EC 33 98 00 2A 00 00 00 98 33 98 00 64 34 98 00 009833C8 2F 00 00 00 B8 34 98 00 F4 34 98 00 2A 00 00 00 009833D8 1C 34 98 00 94 34 98 00 33 00 00 00 B0 33 98 00 009833E8 EC 33 98 00 03 00 00 00 F8 33 98 00 1C 34 98 00 009833F8 02 00 00 00 B0 33 98 00 10 34 98 00 32 00 00 00 00983408 7C 34 98 00 DC 34 98 00 32 00 00 00 28 34 98 00 00983418 F8 33 98 00 32 00 00 00 8C 33 98 00 A0 34 98 00 00983428 30 00 00 00 80 33 98 00 EC 33 98 00 03 00 00 00 00983438 28 34 98 00 A0 34 98 00 01 00 00 00 BC 33 98 00 00983448 AC 34 98 00 32 00 00 00 D4 33 98 00 EC 33 98 00 00983458 2B 00 00 00 D0 34 98 00 B8 34 98 00 02 00 00 00 00983468 10 34 98 00 A4 33 98 00 2E 00 00 00 D0 34 98 00 00983478 88 34 98 00 01 00 00 00 34 34 98 00 C8 33 98 00 00983488 02 00 00 00 34 34 98 00 4C 34 98 00 2D 00 00 00 00983498 98 33 98 00 1C 34 98 00 32 00 00 00 40 34 98 00 009834A8 D4 33 98 00 04 00 00 00 94 34 98 00 34 34 98 00 009834B8 2D 00 00 00 E8 34 98 00 70 34 98 00 30 00 00 00 009834C8 94 34 98 00 8C 33 98 00 31 00 00 00 64 34 98 00 009834D8 40 34 98 00 2F 00 00 00 EC 33 98 00 B0 33 98 00 009834E8 33 00 00 00 88 34 98 00 04 34 98 00 05 00 00 00 009834F8 F4 34 98 00 F4 34 98 00 02 00 00 00 00 00 00 00''' data_dict = {} visit_dict = {} for i, line in enumerate(data.split('\n' )): for j in range(4 ): data_dict[hex_format(0x983378 +16 *i+4 *j)] = little_egg(line[9 +12 *j : 9 +12 *j+12 ]) for key, value in data_dict.items(): print(key, value)
节选一部分数据以供观察其格式:
1 2 3 4 5 6 7 00983380 00000034 00983384 00983398 00983388 0098338C 0098338C 00000002 00983390 00983398 00983394 009833E0
其实就是三个一组,第一个是v7的取值,后二者分别是地址+4和地址+8的两种情形。
最后,程序要求v7的最终值必须是0x4034f4(为方便表述不提及变动的基址)
所以本题的算法可以总结为:
给定一些节点和节点之间的连通关系,寻找一条从0x380到0x4f4的路径。
一旦找到这条路径,我们就可以通过flag[i] = v7+flag[i-1]解得flag.
由于数据量不大,我直接手动寻路。
下面脚本中1表示地址+4的情形,2表示地址+8的情形。
1 2 3 4 5 6 7 8 9 10 v7 = [0x34, 0x2c,0x2a,0x32,0x32,0x01,0x2a,0x02,0x2a,0x2b,0x2d,0x33,0x32,0x01,0x2f,0x05] op = [1,2,1,2,1,1,2,2,1,2,1,2,1,2,2,1] v5 = 48 for i in range(len(v7)): if op[i] == 1: print(chr(v5+v7[i]),end='') v5 = v5+v7[i] elif op[i] == 2: print(chr(v5-v7[i]),end='') v5 = v5-v7[i]
一步到位的python代码 参考了一个c代码,写出了这个脚本。思想就是dfs。参考的网址找不到了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 import stringdef little_egg (s ): return s[10 :12 ] + s[7 :9 ] + s[4 :6 ] + s[1 :3 ] def hex_format (num ): return '00' +hex(num)[2 :].upper() data = '''00983378 98 33 98 00 00 00 00 00 34 00 00 00 98 33 98 00 00983388 8C 33 98 00 02 00 00 00 98 33 98 00 E0 33 98 00 00983398 2C 00 00 00 8C 33 98 00 D4 33 98 00 2A 00 00 00 009833A8 58 34 98 00 94 34 98 00 06 00 00 00 D4 33 98 00 009833B8 EC 33 98 00 2A 00 00 00 98 33 98 00 64 34 98 00 009833C8 2F 00 00 00 B8 34 98 00 F4 34 98 00 2A 00 00 00 009833D8 1C 34 98 00 94 34 98 00 33 00 00 00 B0 33 98 00 009833E8 EC 33 98 00 03 00 00 00 F8 33 98 00 1C 34 98 00 009833F8 02 00 00 00 B0 33 98 00 10 34 98 00 32 00 00 00 00983408 7C 34 98 00 DC 34 98 00 32 00 00 00 28 34 98 00 00983418 F8 33 98 00 32 00 00 00 8C 33 98 00 A0 34 98 00 00983428 30 00 00 00 80 33 98 00 EC 33 98 00 03 00 00 00 00983438 28 34 98 00 A0 34 98 00 01 00 00 00 BC 33 98 00 00983448 AC 34 98 00 32 00 00 00 D4 33 98 00 EC 33 98 00 00983458 2B 00 00 00 D0 34 98 00 B8 34 98 00 02 00 00 00 00983468 10 34 98 00 A4 33 98 00 2E 00 00 00 D0 34 98 00 00983478 88 34 98 00 01 00 00 00 34 34 98 00 C8 33 98 00 00983488 02 00 00 00 34 34 98 00 4C 34 98 00 2D 00 00 00 00983498 98 33 98 00 1C 34 98 00 32 00 00 00 40 34 98 00 009834A8 D4 33 98 00 04 00 00 00 94 34 98 00 34 34 98 00 009834B8 2D 00 00 00 E8 34 98 00 70 34 98 00 30 00 00 00 009834C8 94 34 98 00 8C 33 98 00 31 00 00 00 64 34 98 00 009834D8 40 34 98 00 2F 00 00 00 EC 33 98 00 B0 33 98 00 009834E8 33 00 00 00 88 34 98 00 04 34 98 00 05 00 00 00 009834F8 F4 34 98 00 F4 34 98 00 02 00 00 00 00 00 00 00''' data_dict = {} visit_dict = {} for i, line in enumerate(data.split('\n' )): for j in range(4 ): data_dict[hex_format(0x983378 +16 *i+4 *j)] = little_egg(line[9 +12 *j : 9 +12 *j+12 ]) del data_dict['00983378' ]del data_dict['0098337C' ]del data_dict['00983500' ]del data_dict['00983504' ]class C : def __init__ (self,data,p1,p2,n,visit=False ): self.data = data self.p1 = p1 self.p2 = p2 self.n = n self.visit = visit data_list = [] for i in range(32 ): data = int(data_dict[hex_format(0x983380 + i * 12 )], 16 ) p1 = (int(data_dict[hex_format(0x983380 + i * 12 + 4 )],16 ) - 0x983380 ) // 12 p2 = (int(data_dict[hex_format(0x983380 + i * 12 + 8 )],16 ) - 0x983380 ) // 12 n = i c = C(data,p1,p2,n) data_list.append(c) def visible (n ): return True if chr(n) in string.ascii_letters+string.digits else False def dfs (c,step ): i = c.n if step == 17 and i == data_list[31 ].p1: return True if c.visit: return False data_list[i].visit = True if visible(flag[step-1 ] + c.data): flag[step] = flag[step-1 ] + c.data if dfs(data_list[c.p1], step+1 ): return True elif visible(flag[step-1 ] - c.data): flag[step] = flag[step-1 ] - c.data if dfs(data_list[c.p2], step+1 ): return True else : data_list[i].visit = False return False flag = [48 ] + [0 ]*23 dfs(data_list[0 ], 1 ) print('flag{%s}' % '' .join(list(map(chr,flag[1 :17 ]))))