鸽了好久了。主要是好久没用过mysql了。
0x01 命令
Restart/etc/init.d/mysqld restart
Start/etc/init.d/mysqld start
Stop/etc/init.d/mysqld stop
0x02 数据库语句
参考:
https://www.runoob.com/mysql/mysql-tutorial.html
https://wiki.jikexueyuan.com/project/linux/mysql.html
基础查询
查询当前所有的库 show databases;
选择库 use 库名;
查询库中的表show tables;
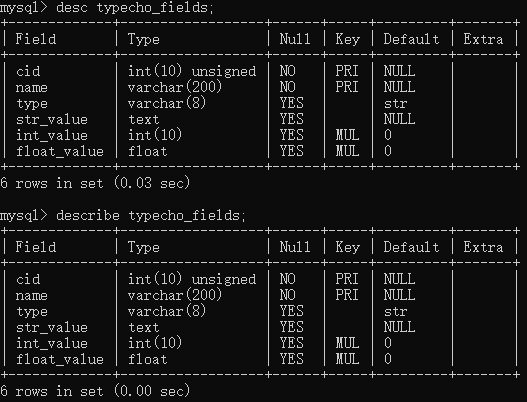
查看表中的字段及类型等 desc 表名;或describe 表名;
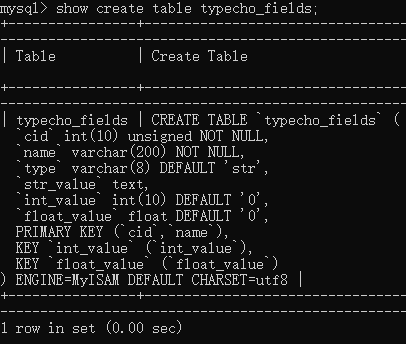
查看某个表的表结构(创建表时的详细结构)show create table func;
增删改查
插入数据:
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN );
删除数据:
DELETE FROM table_name [WHERE Clause];
修改数据:
UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause];
查找数据:
1 | SELECT column_name,column_name |
- 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
- SELECT 命令可以读取一条或者多条记录。
- 你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
- 你可以使用 WHERE 语句来包含任何条件。
- 你可以使用 LIMIT 属性来设定返回的记录数。
- 你可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
导入导出
导出
mysqldump -u root -p database_name table_name > dump.txt
如果完整备份数据库,则无需使用特定的表名称。
导入
mysql -u root -p database_name < dump.txt
或
1 | //mysql内部 |
Linux上数据库备份后导入到win10中失败:

因为linux默认utf8,windows默认gbk。可使用下面的命令导入。
mysql -uroot -p --default-character-set=utf8 blog3 < d:/桌面/blog.sql
注意:
d:/桌面/blog.sql或d:\\桌面\\blog.sql都行,千万不能d:\桌面\blog.sql,因为转义(虽然我仍然没搞明白命令行里又不是mysql语句,为什么会转义)--default-character-set=utf8指定utf8
靠该命令解决了typecho博客数据库在本地导入失败的问题。(之前导入一直用source)
0x03 知识点
utf8
来源:https://www.zhihu.com/question/347040967/answer/832021621
MySQL的utf8是虚假的utf-8,只能存储三个字节,但是无法支持SMP(supplementary multi-lingual plane),包括emoji(这是重灾区),一些生僻的CJK字符,一部分生僻的符号等。对于主要的文字(英文、欧洲各种语种、中文、日文……),3个byte的utf8也算是够用。
UTF8早期的标准RFC2279规定一个UTF8字符是1~6个Byte。这也是为什么早期Mysql把一个UTF8字符设计为6个Byte的原因。但是2003年11月,出了新的标准RFC3629,规定一个UTF8字符是1~4个Byte。
0x04 运维记录
pass
0x05 奇奇怪怪的东西
UTF-8的BOM混入数据库
之前博客的数据库文件备份到本地,想要导入至本地数据库时,却发现导入出错。
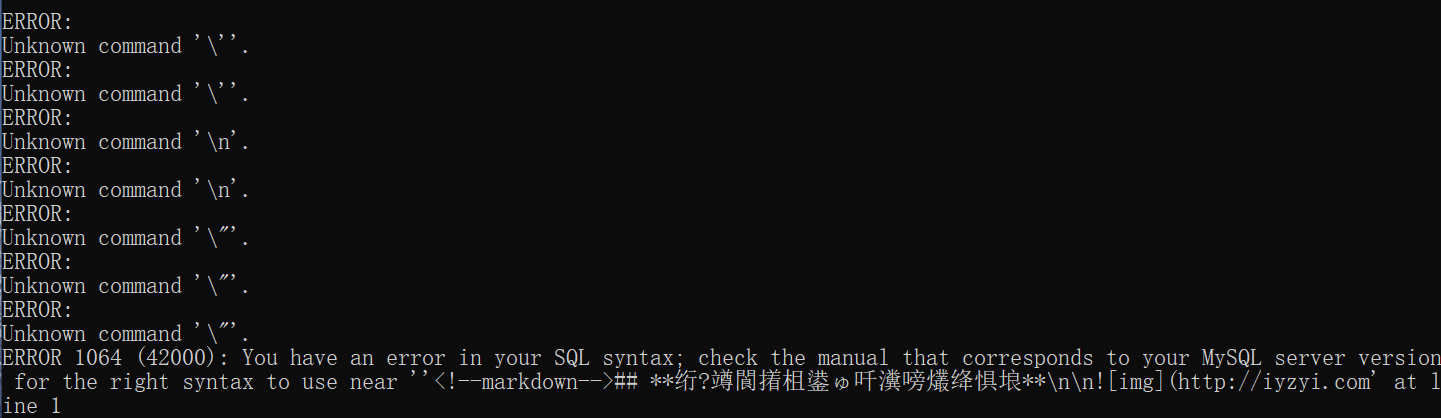
经过排查,
删除这个字符后可成功导入数据库。
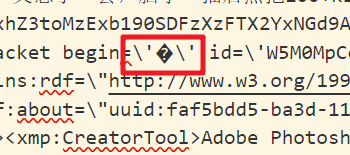
将局部字符复制,用winhex打开,

引自:https://my.oschina.net/JKOPERA/blog/309423
BOM是Byte Order Mark(定义字节顺序),因为在网络传输中分两种顺序:大头和小头。
由于兼容性,带BOM的utf-8在一些browser中显示为乱码。
网上搜索了关于Byte Order Mark的信息:
在UCS 编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little- Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。带BOM的UTF-8,所有PHP无法识别,直接将EF BB BF输出,在charset=”utf-8”的页面中是空白,在GB2312的页面中的输出的就是稀有汉字:锘匡豢
删掉EF BB BF这三个字节,再次导入数据库,发现可以了。
过了半天,我想删掉blog这个数据库,发现删不掉,宝塔或是命令行都无法删库。当我用一个正常字符串替换掉含有BOM的那篇文章后,可以正常删库了。
我还以为发现了一个可以防止恶意删库的新的奇奇怪怪的思路,但是,刚刚在本地数据库中尝试重现时,没有成功复现。可惜了。
0x06 sql注入相关
group_concat
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator ‘分隔符’])
1 | mysql> select cid, group_concat(coid) from typecho_comments group by cid; |