hackim20的另一道逆向题,从逆向的角度来说不是很难,关键是如何将操作自动化。通过本题初步地学习了题目的部署和angr的使用。
misc猜测 给出了3000个二进制文件,观察可知文件分两大类,大小分别是5.34K和5.99K。很容易得知二者分别是32位和64位程序。
首先猜测是否是32表示0,64表示1,构成了二进制串
(虽然这是逆向题,misc的可能性很小,但我还是首先尝试了这种可能)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import os,struct, binasciidef get_FileSize (filePath ): ''' 网上找的小轮子 ''' fsize = os.path.getsize(filePath) fsize = fsize/float(1024 ) return round(fsize,2 ) dirpath = r'D:\桌面\hackim20\RE\year3000\year3000' files = os.listdir(dirpath) files.sort(key=lambda x:int(x[:-4 ])) _bin = '' for file in files: path = os.path.join(dirpath, file) size = get_FileSize(path) if str(size) == '5.34' : _bin += '0' elif str(size) == '5.99' : _bin += '1' o = b'' for i in range(len(_bin)//8 ): char = int(_bin[i*8 :i*8 +8 ], 2 ) & 0x7f o += struct.pack('b' , char) print(o)
输出是
1 b'R\x08!N4\x051J<8wsA8v"EZY&;`]Cv*;=\x11%C\x00C\x0ej\x08\x00?\x0f$ZP\x0e-BB\x1f\x15doY!\x15\x08C\x16J\x0ev\x0e\x00\x0cd\x12+\x1f1p.zXq\x16`\x14& G\\\x04\x1e\x1a\x05!>Z\x161z\x12\x13\x0ej\x1b(<(-Dsz@>4]A\x19~\x08+\x13Bs`X\x7f\x12/\x1d8.\x1f\x0b(\x0fD17\x05\x14`\x1a\x02&m[WhB+=8\x03}\x15-)s6_h"C\x12iA\x196enf.%\x0b!kSQ;3*(gLkB\x1c"g\x07"\x083\x1eA5\x05\x0cYc04\x0e3_!1\t_\x05z$\x10$`\x07\x15qD\x07Kt\x07\x0357Kd0bd2}Y\x15$\x10.zxU=Ke0F\x18Rpj\\H|34/Kk6e\x079k$\x0fkc\x16T\x14\x00y.\x13R\x07^#g\x1b%]\x1ak\x06\\`+\x12 r\x1dV\x7f0K.67c\x17P[gSb{k\x14@H\x7fHyB\x11}];o:B!Oo\x1cf_]\x18\x1b\x1f{Uo;*\r9k_}4L\x10\'\x01"GS\x03N\x1a\x1cL;S\\`\x04AM\x1am}5B\x18\x08>f\x06"d\r\ngno9eWAt2'
好吧,果然不是misc
比较文件差异 猜测同一类的文件应该存在细小的差异。
1.bin和3.bin都是5.34KB的文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@izwdpnodbapihwz dist]# cmp -l 2.bin 4.bin 645 40 26 646 321 354 647 200 321 648 331 77 649 343 35 650 230 101 651 114 33 652 155 37 653 152 71 654 144 222 655 40 252 656 73 65 657 112 153 658 277 176 659 242 305 660 271 7 661 13 315 662 334 265 663 131 150 664 221 143 2074 123 115 2081 116 167 4113 224 363 4114 54 143 4115 211 171 4116 342 134 4117 342 321 4118 250 216 4119 301 77 4120 54 312
使用cmp命令比较。
第一列是序号(偏移文件首部的字节数),表示两个二进制文件何处的数据存在差异,是十进制数。
第二三列分别表示两文件在差异处的数值分别是多少。注意,是八进制数 。
可以发现有三处,分别是605附近,2074附近,4113附近。
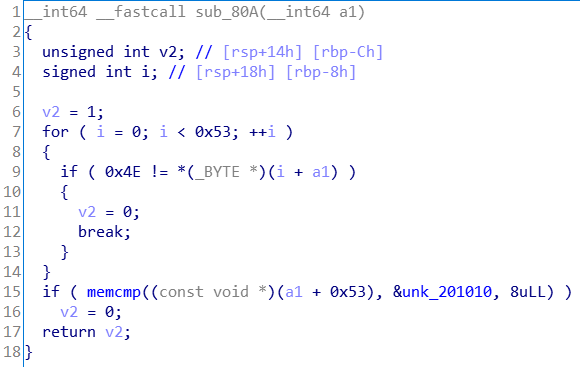
手动payload 下图是程序主体:
进入判断函数sub_80A:
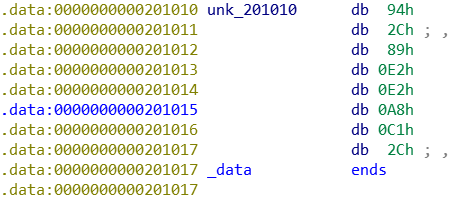
unk_201010的数据为:
所以就是判断输入是否为0x53个0x4e对应的字符拼接上unk_201010对应的字符串。
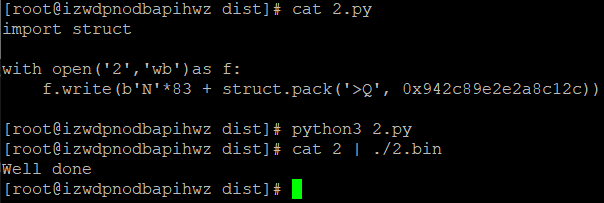
写个小脚本测试一下2.bin的输入:
1 2 3 4 5 6 import structwith open('2' ,'wb' )as f: f.write(b'N' *83 + struct.pack('>Q' , 0x942c89e2e2a8c12c ))
因为python3print 的二进制字节流本质上是个字符串,所以我先把二进制字节流保存到文件中,再通过管道命令重定向输出到2.bin中。得到了well done的回执,说明没毛病。
题目的线上部署 由于题目需要nc连接,而比赛通道早已关闭,幸好出题人赛后给出了docker,我们需要自行部署。
我fork的:https://github.com/iyzyi/hackim-2020
docker都给出了,其实部署就很简单了。
1 2 3 4 git clone https://github.com/iyzyi/hackim-2020 cd /root/tmp/hackim-2020/re/year3000 docker build -t year3000 . docker run -it --name year3000 -p 50011:1234 year3000
50011换成自己的宿主机开放端口。
nc连接一下:
无意间发现:
题目是随机选取几个*.bin,要求你输入base64编码后的payload
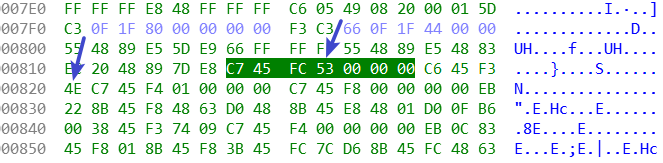
自动化 可以通过上面说的cmp的命令,也可以在ida内结合下面两张图来确定偏移量。
(鼠标点击汇编代码,hex窗口会自动跟随定位位置)
经过对照发现:
1 2 2074处的八进制数值123即为0x53 2081处的八进制数值116即为0x4e
不过注意unk_201010 在ida中显示的地址是0x201010,但是二进制程序没有此地址,最大地址才0x1500多一点。结合cmp的结果,我发现其在文件中的地址为4112,注意不是cmp结果中的第三部分的第一个差异的地方,这个要结合ida的unk_201010的值来看。
以上是64的分析,32位同理。
以下是我的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import os, struct, re, base64from pwn import *def get_FileSize (filePath ): fsize = os.path.getsize(filePath) fsize = fsize/float(1024 ) return round(fsize,2 ) def payload_32 (filepath ): count_addr = 0x661 char_addr = 0x668 data_addr = 4104 file = open(filepath, 'rb' ).read() count = struct.unpack('b' , file[count_addr])[0 ] char = file[char_addr] data = file[data_addr:data_addr+4 ] print count*char + data return count*char + data def payload_64 (filepath ): count_addr = 0x819 char_addr = 0x820 data_addr = 4112 file = open(filepath, 'rb' ).read() count = struct.unpack('b' , file[count_addr])[0 ] char = file[char_addr] data = file[data_addr:data_addr+8 ] print count*char + data return count*char + data def payload (filepath ): if get_FileSize(filepath) == 5.34 : return payload_32(filepath) elif get_FileSize(filepath) == 5.99 : return payload_64(filepath) def main (): context.log_level = 'debug' i = remote('iyzyi.com' , 50011 ) ''' file = '2.bin' dirpath = '/root/tmp/dist' filepath = os.path.join(dirpath, file) payload(filepath) ''' recv = '' while 'hackim' not in recv: file = i.recvuntil('>' ) r = re.search(r'(\d+?)\.bin' , file) if r: file = r.group(1 ) + '.bin' dirpath = '/root/tmp/dist' filepath = os.path.join(dirpath, file) i.sendline(base64.b64encode(payload(filepath))) main()
脚本和3000个*.bin放在一起,而且要修改dirpath为相应的值哦。
思路相近的大佬: 以下脚本摘录自https://x3ero0.tech/posts/year3000/ ,纯英文,也是难为我了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 from pwn import *import base64context.log_level = "critical" def solve (filename ): file = open(filename, "rb" ).read() ELF64_Coun = 0x816 ELF64_Valu = 0x81d ELF32_Coun = 0x65e ELF32_Valu = 0x665 ELF64_Addr = 0x1010 ELF32_Addr = 0x1008 Format = ord(file[0x04 ]) if (Format == 2 ): context.update(arch='amd64' , os='linux' ) code_count = file[ELF64_Coun : ELF64_Coun+7 ] code_value = file[ELF64_Valu : ELF64_Valu+4 ] disa_count = disasm(code_count) disa_value = disasm(code_value) code_count = int(disa_count.split('0x' )[-1 ], 16 ) code_value = chr(int(disa_value.split('0x' )[-1 ], 16 )) value = file[ELF64_Addr : ELF64_Addr+8 ] value_n = u64(value) flag = code_value * code_count + value elif (Format == 1 ): context.update(arch='i386' , os='linux' ) code_count = file[ELF32_Coun : ELF32_Coun+7 ] code_value = file[ELF32_Valu : ELF32_Valu+4 ] disa_count = disasm(code_count) disa_value = disasm(code_value) code_count = int(disa_count.split('0x' )[-1 ], 16 ) code_value = chr(int(disa_value.split('0x' )[-1 ], 16 )) value = file[ELF32_Addr:ELF32_Addr+4 ] value_n = u32(value) flag = code_value * code_count + value return flag def main (): dump = "" i = 0 p = remote("re.ctf.nullcon.net" , 1234 ) a = "" temp = "" while ('hackim' not in dump): if (i==10 ): print "Flag: " + p.recvline() p.close() exit() file = p.recvline().strip() a = p.recvuntil("> " ) solver = solve(file) p.sendline(base64.b64encode(solver)) temp = p.recvline() if ("Well done" in temp): print "[0x%.4x]\t" % i+ file + '\t: Well Done' else : print "[+] Failed:\t" + file + "\tdumping recieved data" exit() i += 1 if __name__ == "__main__" : main()
我使用文件大小来区分32位和64位没有普适性,这位大佬采用的Format = ord(file[0x04])区分。受教了。
他脚本的disasm其实是类似于ida中一整行的汇编代码,左边是行号,中间是汇编代码(对于此偏移量处的汇编代码,其实就是一个单纯的数字),右侧是啥我忘了,好像是注释来着??反正我觉得他的提取方法不如我的好,直接从文件中读偏移。
angr 参考自https://mrt4ntr4.github.io/Nullcon-HackIM-Year3000/
源代码是python2,我改成了python3
当然本代码只是能暴力出所有的payload而已,没有nc的功能。仅作演示angr的使用吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import angr,claripy import sys,csv,time from base64 import b64encode import logging logging.getLogger('cle.loader').setLevel('ERROR') w = csv.writer(open("output.csv", "a")) def solve(path): begin = time.time() proj = angr.Project(path) state = proj.factory.entry_state(add_options={angr.options.LAZY_SOLVES}) simulation = proj.factory.simgr(state) def success(state): output = state.posix.dumps(sys.stdout.fileno()) return b'Well done' in output def failed(state): output = state.posix.dumps(sys.stdout.fileno()) return b'You have failed' in output simulation.explore(find=success, avoid=failed) if simulation.found: sol_state = simulation.found[0] sol = sol_state.posix.dumps(sys.stdin.fileno()) print ("({} secs)".format(round(time.time()-begin,2))) enc = b64encode(sol) w.writerow([path, enc]) print (enc) else: print( "No Sol found for {}".format(path)) if __name__ == '__main__': for x in range(1,3000): solve("{}.bin".format(x))
一些问题 没搭建成功,可能是python版本冲突??待排查TODO
然后找到了官方的docker,然鹅一直出问题,好不容易才跑成功。
下面的命令用于启动:
1 docker run -it --name angr -v /root/tmp/dist:/home/angr/dist --privileged=true angr/angr
docker挂载数据卷 不加上--privileged=true的话,关于文件的读写都会报权限不足的错误,su root也不行,因为挂载了数据卷,docker的root相对于宿主机仍然是普通用户。
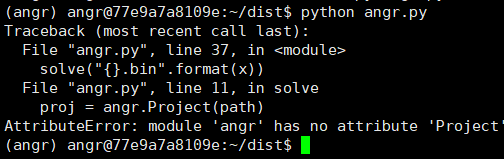
angr模块没有’Project’ 这个问题把我逼疯惹~
我还以为是docker的锅,没想到最后无意间发现,我的脚本的名字是angr.py。
和模块的名字的命名空间发生了冲突。
这个问题我之前写re.py的时候就被坑过,只能说太容易出问题了。
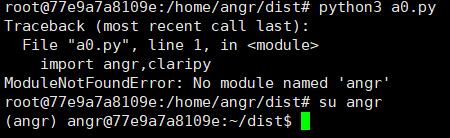
No module named ‘angr’ 请切换到angr用户运行脚本
运行
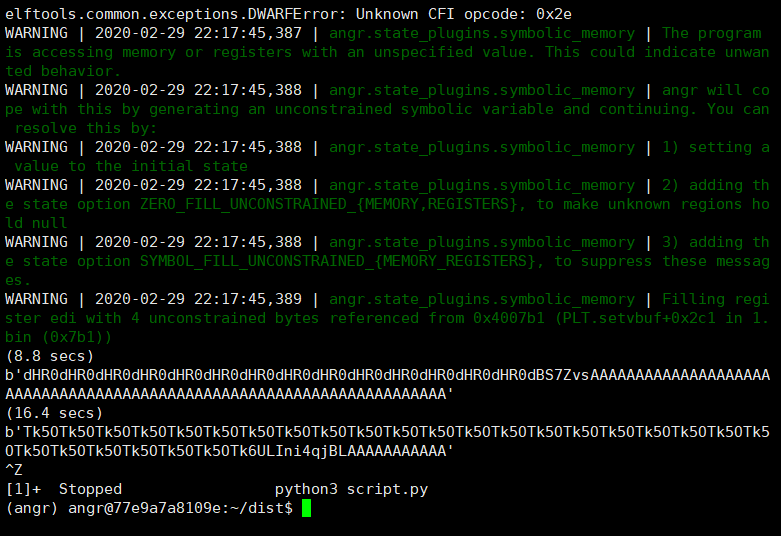
只运行到第二条payload,仅作演示。